
Exploring Institutional Structures and Individual Networks
by Helen Birkett
I’ve been in residence at the Traveler’s Lab this semester and have taken the opportunity to work with Wesleyan students to extend my study of Caesarius of Heisterbach’s social network. The results, so far, are promising…
Background
My project uses the Dialogue on Miracles by Caesarius of Heisterbach (c.1180-c.1240) as a case study for investigating the structure of Cistercian social networks c.1200. Caesarius was a monk at the Cistercian abbey of Heisterbach in Germany and my project examines the social interactions recorded in his most famous work, the Dialogue on Miracles, which was written in the late 1210s and early 1220s. I started this project as a way of exploring the possibilities of network analysis and to test out a hypothesis that underlay my work on interactions between Cistercians in Britain at around the same time.
The Cistercian order developed a particularly extensive and regular system of communication between its abbeys. This was partly the result of the way in which the order expanded: new houses were founded by a group of monks setting out from one community, the mother house, to begin another, a daughter house. This meant that the Cistercian order was structured like a family tree in which each community could trace its relationship back to Cîteaux, the founding house, through lines of filiation. Importantly, the Cistercians used these relationships to maintain discipline and uniformity in the order: each year the abbots attended an annual general chapter at Cîteaux; and each year the abbot of a mother house was required to visit each of the abbey’s daughter houses.
My research investigates how this structure functioned as a communication network for the transmission of miracle stories. Although sparse and sporadic, my British source material was already suggesting that this structure was less important in the transmission of stories than I had anticipated. The Dialogue on Miracles, a large work of 746 chapters in 12 books or 805 stories, provided a much bigger dataset with which to test these ideas. It also gave me the chance to compare new digital approaches with the more traditional analytic techniques employed by Brian Patrick McGuire in his classic study of Caesarius’ social network.
Research Questions
I began research on this project a couple of years ago in collaboration with Pádraig Mac Carron, a physicist and network analysis expert at the University of Oxford. The project is based on two main research questions:
- How useful is network analysis for understanding the transmission of exempla in the Dialogue on Miracles?
- To what extent does Caesarius’ communication network correspond to Cistercian lines of filiation?
The first question is the more explorative, fun one – it really asked, can I use network analysis to look at this material? The initial response to this was… kind of. I created a database of interactions that recorded Caesarius’ sources for his stories, which Pádraig converted into a visualization. However, the resulting ‘network’ was limited and artificial – as might have been expected from the nature of the sample, it was almost entirely based on Caesarius. The addition of the few stories which had a provenance not directly linked to Caesarius (i.e. he doesn’t tell us how he heard them) did little to complicate the picture (these are the red dashed lines below).

The second question engaged with this data in a more sophisticated way and provided some more promising insights. My research showed that while some of the interactions in Caesarius’ text followed expected lines of filiation, a surprising number of interactions jumped between filiations.
Caesarius at the Lab
My collaboration with the Traveler’s Lab is allowing me to pursue these questions further. Two Lab members, Rachel Chung and Rebecca Greenberg, are working with me to create an extended dataset that records the interactions within the stories themselves. Our aim is to use this new, extended dataset to complicate Caesarius’ network – to use interactions in the more fictionalised narratives of the text to offer a more realistic picture of the Dialogue’s social world (it’s a conceit that appeals strongly to my literary side!). This extended dataset should also offer further insights into the question of Cistercian communication structures vs social reality.
This new dataset includes only direct interactions between identifiable individuals. This means it excludes implied relationships (such as familial relationships) unless the two individuals talk, write to each other, or interact directly in some way. This does create an element of artificiality in the data, but it also means we focus on who is actually talking to whom rather than expected interactions. We’re also only listing identifiable individuals to make sure that we can merge these datasets and networks successfully. As a result, I’ve had to refine my original dataset for Caesarius’ sources, which included a lot of anonymous individuals and the potential for double-counting.
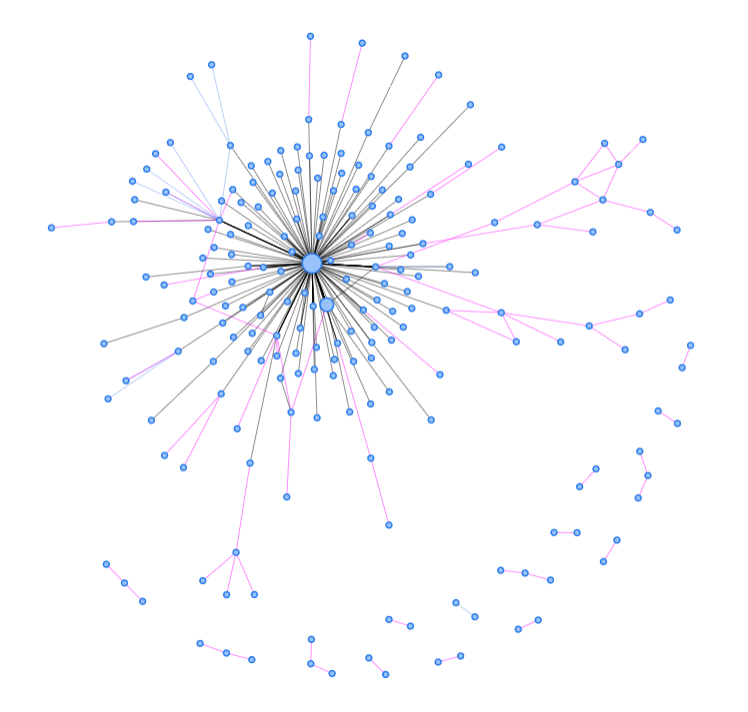
Currently, we are a third of the way through the data and the results are promising. This visualization, produced by another Lab member, Liza Kravchenko, shows the integrated networks of Caesarius’ sources (black), the additional external sources for his stories (blue), and the interactions within the stories themselves (pink). The nature of the material means that Caesarius will always dominate this network, but this visualization suggests that something more complex and realistic is starting to emerge.
Further Research
As usual, creating one dataset prompts you to think about creating another to offer a fuller or slightly different analysis of the material. Here it’s become clear that a dataset of family networks within the text would be a useful way of investigating individual and institutional connections, and something that should be integrated into the social network of the Dialogue. We could also extend our dataset to include interactions with divine beings, although I remain unconvinced of the value of doing this. Finally, my attendance at the Social Science History Association Conference in Montreal last weekend drew my attention to other ways of visualising textual data, which might be used to make simple, but effective points, about the geographical or thematic biases of my material. These visualizations were based on qualitative data analysis (QDA), which is pretty easy if you have clear search terms but, if not, will be a much more labour-intensive process – and I need to give more thought as to whether the effort involved here is really worth the result.