
By Arla Hoxha
During summer 2024, Lab Manager Arla Hoxha ’25 continued developing Traveler’s Lab Comparing Chronicles Project through a QAC (Quantitative Analysis Center) Summer Fellowship. Throughout the summer, she experimented with different statistical methods and software and explored how new methods might be utilized to better compare different manuscripts from the Annals of Fulda. The summer research process culminated in a poster presentation session summarizing the progress of Chronicles up to that point, as well as visual representations of our work.
The presentation started off by giving a definition of the event unit for a general audience unfamiliar with our work. In recent years, there has been an effort in the field to shift the focus from the chronological development of historical texts and towards the development of the narrative. Events do not always show up in a narrative as they occur chronologically; they are compiled by an author who chooses what events to include and how to arrange them. Studying chronicles using ‘years’ as units reveals little about the chronicle and even less about its author as it is too broad and unable to capture the nuance of meaning in the language and the way text is ordered. The intervention of the Chronicles Project so far is the alternative unit of observation; the event defined as a string, spanning from a few words to paragraphs, with a central theme (event types), consistent named tag entities (characters and setting), terminating with a change of temporal identifiers or agents in the narrative. We expand more on these definitions in our previous methodologies.
Using a narrative-focused approach in the study of chronicles and the unit of the ‘event’ we explore chronicle entries from the Annals of Fulda—the text which continues to be our main focus—and determine how events differ on the manuscript level. The focus of the summer research was reducing events to their differentiating components and using different text analysis tools to compare these components across events to determine event similarity. We experimented with Python text mining libraries such as spaCy to filter the entries. spaCy is an open-source library used for Natural Language Processing (NLP) in Python. The program developed takes a csv file with the event titles, years and manuscripts. It then splits the title into its components, then using spaCy’s tokenization feature it tags each component into parts of speech and then tries to match entries based on named entities, verbs, etc. This method of filtering can also easily be accomplished through Nodegoat. The idea behind using event titles for the comparison is that they are supposed to capture the event and utilize specific verbs from the event that are representative.
An interesting function spaCy allows is comparing words and giving their similarity through a percentage (cosine similarity model), which can be utilized to compare two similar verbs used in an event title—this could be used to match events that are potentially the same although they have been differently labeled, forgoing the issue of human error. ‘Northmen attacked’ and ‘Northmen plundered’ do not have the same label, nor are their passages textually the same. But we can filter events by year and look for different manuscripts, then differentiate between events based on their type categorizations; checking for cosine similarity above a certain value can help us determine whether ‘plundered’ and ‘attacked’ have a similar meaning and therefore ‘Northmen plundered’ and ‘Northmen attacked’ would be understood as referring to the same event. However, this functionality comes with its own problems; it is limited by the library’s vocabulary and its efficiency is undermined by lack of accuracy. Moreover, even though the verbs used in the titles are important this method overemphasizes the way events are titled over other elements. The accuracy can be increased by training a module using data that is specific to our project. For now, we can go through the process of determining if two verbs are similar enough using a human reader, which is a slower but more accurate process. Although this is beyond the scope of our project as of now, it might be interesting in the future to train a module that is specific to the Chronicles Project, which could prove useful in automatizing part of the process of detecting the same event.
Returning to the main topic of comparing events, two events are the same as long as they speak of the same event; that is the same event type (see Diana Tran’s Event Type methodology here), with the same named entities. Whether they are textually the same is less important. We found events that spoke of the same occurrence by filtering (through the method described above as well as Nodegoat filters) for events with the same title happening in the same year but different manuscripts. An instance of this is ‘Pope Hadrian dies’ in year entry 885 for both manuscripts 2 and 3 in Annals of Fulda:
![]()

The passage differs between manuscripts, but the central idea captured in the title remains: ‘Pope Hadrian died.’ Despite the first event including more details surrounding the death of Pope Hadrian and the difference in length of the two event entries, both refer to the same event. Beyond the categorization under the same title, the events in both manuscripts are cataloged under event type ‘Birth/Death’ and both have ‘Pope Hadrian’ listed as a principal actor. The way the event is named is helpful in communicating the ideas of the passage and helping us identify them correctly. Here we see how ‘Even Types’ can be a powerful tool in determining event similarity as well as understanding distribution of events across time. We believe that the categorization of events by event types will increase the accuracy of determining ‘same’ events.
Of course, over relying on Event Types presents the caveat of human error that is built into this categorization. We observe that chronicle year entries with largely the same events have different distributions of event type tags:
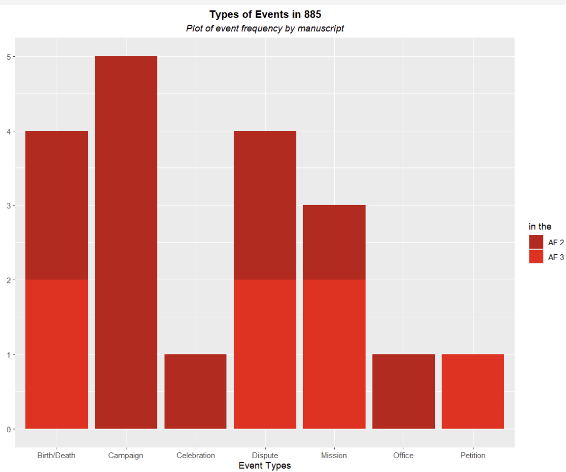
The data in use is the cross-referenced chronicle transcript from the different manuscripts of the Annals of Fulda stored through the Nodegoat environment. The parsing of the data and visuals were completed using Google Sheets for data management and plotting libraries in R.
What is the importance of determining events that are the same across manuscripts and chronicles? By pointing out the similarities between events we are able to discern their differences as well and start asking questions about authorship and the context in which different manuscripts emerged. The same methodology we have been using on events from different manuscripts of Fulda is to be applied to events that pertain to different but overlapping chronicles in the future.
Through the work done this summer, determining event similarities we found overlap in a few events from different manuscripts. We attempted to tag text from different manuscripts describing the same event under the same event tag, so we tried to list the passage of events from different manuscripts under the same event object entry. Perhaps the most important result from our work this summer was noticing the issues with our old model of event categorization. Our old model required the passage to be written out on the event description; in the case of two events we would have to do so for both passages and so on depending on the number of manuscripts that describe the same event. Our future goal is to be able to cross reference the English text with the original Latin, this would require us to list another passage under the event entry. We realized that this methodology would become increasingly more insupportable. Moreover, the work comparing chronicles in this way made apparent certain redundancies in our data. Most notably, named entities appeared twice; as tags in the chronicle object and cross-referenced in the object descriptors of events.
To reduce the redundancy in our data and to make the process more efficient moving forward, we implemented a mass restructuring. The new objects are as follows:

Chronicle Entry is now the object that contains passages. Passage is the object where named entities are tagged—previously this was done in Chronicle Entry. Now events are linked to the chronicle entry through the Passage object. The passage is cross referenced in the object description of the event, but the event is not tagged in Passage as to reduce redundancy. Named entities on the other hand appear as tags in Passage, but they are not cross referenced in Event, because Passage already contains them, and Passage is cross listed in Event.
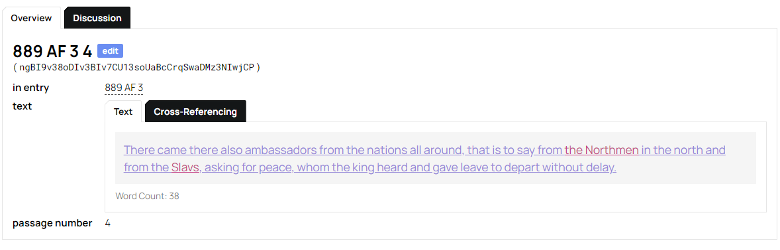
Here is an example of the Passage object: ‘in entry’ is the link to the Chronicle entry, which in turn is linked to the object ‘Chronicle’ which stores the references to the source texts, i.e.: the English translations of Annals of Fulda. The text is the passage, as well as the text of the event in question. Passage number shows where the passage/event occurs in relation to the other events in that same year, emphasizing the progression of narrative over chronological progression, one of our main goals that we have previously had issues representing in Nodegoat.
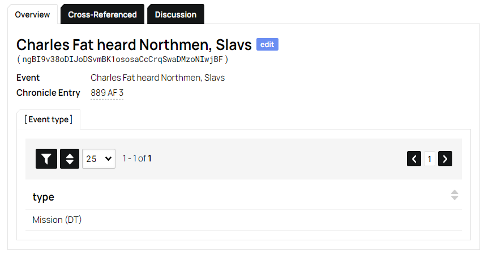
The event no longer has description tags for ‘Places’ and ‘Person’ because those are tagged in Passage and can be cross-referenced through it. This also makes the work of referencing multiple passages under the same Event much easier; instead of writing down multiple events in the description of the Event object, they can be cross-referenced. This will also aid us in the eventual transition to Latin. The only elements directly listed under Event are the event title, Chronicle entry, and in the sub object, the Event Type.
Other smaller but not insignificant improvements to the model were cleaning up the data of the Person and Places objects where each entry was filled out with relevant information that was previously missing, such as birth and death days for Person and coordinates for Places. In the process is also the development of types of locations to categorize Places.